
To talk about data quality is a double-edged sword. You risk losing the attention of your audience, but at the same time, you know that you are addressing one of the most critical issues in data science.
We know that data quality and concerns around this topic are one of the major stumbling blocks in all data lake development projects. If we cannot find a pragmatic approach towards data quality aspects, release dates might be delayed, or the whole project might fail before contributing real value to your organization.
The key to mastering data quality is in taking a pragmatic approach. Since data quality is a multi-dimensional problem there is no “one size fits all” type of solution. The right path will be different for each question that you want to answer. I am reminded of status data information (“logbook data”) from wind turbines, where the question of how to structure and manage the data depends also on how one intends to analyze these data sets. But this is a different story…
So, what does pragmatism mean with respect to data quality and what is our advice?
First, you need to establish clear data quality standards, such as accuracy, completeness, and consistency. Keep in mind that these standards should be realistic and based on the actual data streams that you are trying to manage.
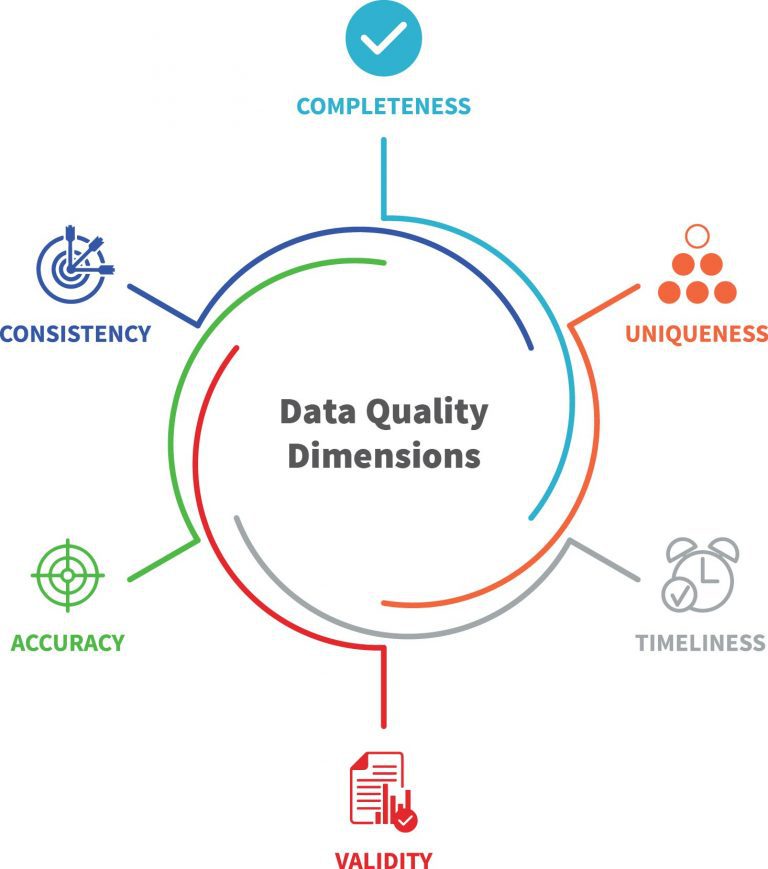
If you already have your data lake in place, you should perform regular data audits or regular data quality monitoring. In the renewable energy industry, assets are distributed, environmental conditions can be harsh and internet coverage is sometimes quite poor. Therefore, you need to stay on top of the data streams, making regular checks and minimizing data losses wherever possible.
Before you really attack the topic of automatic data cleaning and backfilling, be sure to involve data stakeholders. Data owners, data users or stewards should be involved in the definition of the minimum data quality in the data lake. The use cases of these stakeholders will help you to make sure you don’t aim too high, especially in respect of the minimum requirements.
Of course, you can also evaluate the usage of automated tools that help you identify and potentially correct data quality related issues in your datasets. But again, don’t aim too high, just deal with specific aspects of data quality that are relevant for the actual analysis tasks that should be performed later.
One aspect that is often missed, or at least managed inadequately, is data labeling. If we try to follow a datapoint from the source, e.g., via the data lake and accessed through an output API, we will see a lot of potential for incorrect mapping. For example, if we want to talk with an OEM about the gearbox oil temperature, we should be able to tell the exact name of the data point in the OEM SCADA, OPC interface or database. Even though this seems trivial, it is by no means an industry standard, and generally this is left to data owners to establish best practice, to ensure full transparency and constant availability of this information.
Taken to a multidimensional level, when you zoom out to the macro scale and exit the data lake environment, you’ll observe that an increasing number of aspects must be considered. Assume, for example, that your main goal is to deliver reliable reports on energy production. In this case, would you need to worry about temperature data and its consistency? No, your focus should be on cumulative energy counter values, for example. However, if your goal is to achieve best practices in predictive maintenance, the quality of temperature data becomes crucial. As monitoring cumulative values and temperature data can be entirely distinct tasks, you may want to address these two issues using different approaches.
For certain types of analysis, on-the-fly data cleaning might suffice, eliminating the need to enforce minimum standards within the data lake. Having a tool that acts like a firewall to your data stream, before it enters the analysis process could be a perfect solution and will help you to focus your efforts on more important subjects. For other uses cases, you might want to make sure that the data in the data lake is corrected to reflect the best possible data that you could have. Whether this is a manual or an automated process will depend on the accuracy requirements of the analysis that you wish to perform.
This means that one type of problem might require a frontend solution to visualize the data and any performed corrections, while for another you may not even need to know which data is filtered out, if you’re only concerned with the analytical outcomes. We at SkySpecs have learned that you can extract a lot of business intelligence out of data even if it is of poor quality, just by making sure the data is handled correctly before processing. We have developed SkySpecs Performance with a firewall to ensure that we get the maximum value of the data in any situation.
Let’s be realistic and let‘s solve data quality issues iteratively and intelligently, so that concerns around this topic will not stop us all from adding value to our organizations by crafting business intelligence out of the ore in our data mines.


